

How To Find Duplicate Rows In Sql
Summary: in this tutorial, y'all volition learn how to utilise the Grouping Past clause or ROW_NUMBER() function to discover indistinguishable values in a table.
Technically, you use the UNIQUE constraints to enforce the uniqueness of rows in 1 or more columns of a table. All the same, sometimes yous may detect duplicate values in a table due to the poor database design, awarding bugs, or uncleaned information from external sources. Your job is to place these indistinguishable values in effective means.
To notice the duplicate values in a table, you lot follow these steps:
- Beginning, define criteria for duplicates: values in a unmarried cavalcade or multiple columns.
- Second, write a query to search for duplicates.
If you want to also delete the duplicate rows, you tin can go to the deleting duplicates from a table tutorial.
Let'south set a sample table for the sit-in.
Setting upwardly a sample tabular array
First, create a new table named t1 that contains three columns id, a, and b.
DROP Tabular array IF EXISTS t1; CREATE Table t1 ( id INT IDENTITY(ane, 1), a INT, b INT, Main Cardinal(id) );
Lawmaking language: SQL (Structured Query Linguistic communication) ( sql ) Then, insert some rows into the t1 tabular array:
INSERT INTO t1(a,b) VALUES (1,1), (1,2), (ane,3), (2,ane), (i,ii), (1,3), (ii,one), (2,2);
Code language: SQL (Structured Query Language) ( sql ) The t1 table contains the following duplicate rows:
Lawmaking language: SQL (Structured Query Language) ( sql )
(1,two) (two,1) (1,3)
Your goal is to write a query to find the to a higher place duplicate rows.
Using GROUP By clause to notice duplicates in a table
This statement uses the GROUP BY clause to detect the duplicate rows in both a and b columns of the t1 table:
SELECT a, b, COUNT(*) occurrences FROM t1 GROUP By a, b HAVING COUNT(*) > 1;
Code language: SQL (Structured Query Linguistic communication) ( sql ) Here is the event:
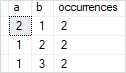
How it works:
- First, the
GROUP BYclause groups the rows into groups by values in bothaandbcolumns. - Second, the
COUNT()part returns the number of occurrences of each grouping (a,b). - Third, the
HAVINGclause keeps only duplicate groups, which are groups that accept more than i occurrence.
To render the entire row for each duplicate row, y'all bring together the upshot of the in a higher place query with the t1 tabular array using a mutual table expression (CTE):
WITH cte As ( SELECT a, b, COUNT(*) occurrences FROM t1 GROUP BY a, b HAVING COUNT(*) > 1 ) SELECT t1.id, t1.a, t1.b FROM t1 INNER Bring together cte ON cte.a = t1.a AND cte.b = t1.b ORDER By t1.a, t1.b;
Code language: SQL (Structured Query Linguistic communication) ( sql ) Hither is the output:
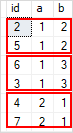
Mostly, the query for finding the duplicate values in one cavalcade using the GROUP BY clause is as follows:
SELECT col, COUNT(col) FROM table_name GROUP BY col HAVING COUNT(col) > one;
Code language: SQL (Structured Query Language) ( sql ) The query for finding the duplicate values in multiple columns using the GROUP BY clause :
SELECT col1,col2,... COUNT(*) FROM table_name GROUP Past col1,col2,... HAVING COUNT(*) > 1;
Code language: SQL (Structured Query Language) ( sql ) Using ROW_NUMBER() function to observe duplicates in a table
The following statement uses the ROW_NUMBER() function to detect indistinguishable rows based on both a and b columns:
WITH cte As ( SELECT a, b, ROW_NUMBER() OVER ( PARTITION BY a,b Club Past a,b) rownum FROM t1 ) SELECT * FROM cte WHERE rownum > 1;
Code language: SQL (Structured Query Language) ( sql ) Here is the upshot:
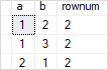
How it works:
Starting time, the ROW_NUMBER() distributes rows of the t1 table into partitions by values in the a and b columns. The duplicate rows will take repeated values in the a and b columns, simply dissimilar row numbers equally shown in the following picture:
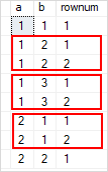
2nd, the outer query removes the first row in each group.
Generally, This statement uses the ROW_NUMBER() role to find the indistinguishable values in one column of a tabular array:
WITH cte AS ( SELECT col, ROW_NUMBER() OVER ( Division BY col Social club BY col) row_num FROM t1 ) SELECT * FROM cte WHERE row_num > 1;
Code linguistic communication: SQL (Structured Query Linguistic communication) ( sql ) In this tutorial, you have learned how to use the Grouping By clause or ROW_NUMBER() function to find duplicate values in SQL Server.
Source: https://www.sqlservertutorial.net/sql-server-basics/sql-server-find-duplicates/
Posted by: hernandezwinger.blogspot.com
0 Response to "How To Find Duplicate Rows In Sql"
Post a Comment